Stateful transformations use the state store for processing input records and creating output from them. Aggregations, joins, and windowing operation need state stores of each previous stream processors (tasks) to accumulate the final status of the elements.
In this topic, Stream DSL stateful transformations is being examined with samples. Sample logics is developed using Java 8. Stream API dependency is defined like below.
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>- Aggregating Transformations
Aggregate (non-windowed): This method is used for aggregating non-windowed values of the records by group id. The difference from reducing transformation is to allow different type values can be aggregated as output. Word count case is simulated using aggregate method as below.
package com.onurtokat.stateful_transformations; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.Serdes; import org.apache.kafka.common.utils.Bytes; import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsBuilder; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.Topology; import org.apache.kafka.streams.kstream.*; import org.apache.kafka.streams.state.KeyValueStore; import java.util.Arrays; import java.util.Properties; import java.util.concurrent.CountDownLatch; public class AggregationTransformation { public static void main(String[] args) { //prepare config Properties config = new Properties(); config.put(StreamsConfig.APPLICATION_ID_CONFIG, "aggregation-transformation-application"); config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> kStream = builder.stream("agg-table-source-topic"); KStream<String, Long> kStreamFormatted = kStream.flatMapValues((key, value) -> Arrays.asList(value.split("\\W+"))).selectKey((key, value) -> value) .mapValues(value -> 1L); kStreamFormatted.groupByKey(Grouped.<String, Long>as(null) .withValueSerde(Serdes.Long())) .aggregate(() -> 0L, (aggKey, newValue, aggValue) -> aggValue + newValue, Materialized.<String, Long, KeyValueStore<Bytes, byte[]>> as("aggregated-stream-store") .withKeySerde(Serdes.String()) .withValueSerde(Serdes.Long()) ).toStream().to("agg-output-topic", Produced.with(Serdes.String(), Serdes.Long())); Topology topology = builder.build(); KafkaStreams kafkaStreams = new KafkaStreams(topology, config); CountDownLatch countDownLatch = new CountDownLatch(1); // attach shutdown handler to catch control-c Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") { @Override public void run() { kafkaStreams.close(); countDownLatch.countDown(); } }); try { kafkaStreams.start(); countDownLatch.await(); } catch (Throwable e) { System.exit(1); } System.exit(0); } }
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic agg-table-source-topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic agg-output-topicbin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic agg-output-topic \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer

Aggregate (windowed): Same as aggregate, but aggregation is done in a defined time period (seconds, minutes, etc.).
package com.onurtokat.stateful_transformations; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.Serdes; import org.apache.kafka.common.utils.Bytes; import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsBuilder; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.Topology; import org.apache.kafka.streams.kstream.*; import org.apache.kafka.streams.state.WindowStore; import org.slf4j.Logger; import java.time.Duration; import java.util.Arrays; import java.util.Properties; import java.util.concurrent.CountDownLatch; public class WindowedAggregationTransformation { private static Logger log; public static void main(String[] args) { //prepare config Properties config = new Properties(); config.put(StreamsConfig.APPLICATION_ID_CONFIG, "windowedAggregation-transformation-application"); config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); StreamsBuilder builder = new StreamsBuilder(); //basic stream KStream<String, String> kStream = builder.stream("windowedAggregation-source-topic"); //format with splitting one line to words //and marked with 1 number KStream<String, Long> formattedKstream = kStream .flatMapValues(value -> Arrays.asList(value.split("\\W+"))) .selectKey((key, value) -> value).mapValues(value -> 1L); //group stream and operate windowed aggregation KTable<Windowed<String>, Long> timeWindowedAggregatedStream = formattedKstream .groupByKey(Grouped.<String, Long>as(null) .withValueSerde(Serdes.Long())) .windowedBy(TimeWindows.of(Duration.ofSeconds(5))) .aggregate( () -> 0L, /* initializer */ (aggKey, newValue, aggValue) -> aggValue + newValue, /* adder */ Materialized .<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store") .withValueSerde(Serdes.Long())); timeWindowedAggregatedStream.toStream().to("windowedAggregation-output-topic", Produced.with( WindowedSerdes.timeWindowedSerdeFrom(String.class), Serdes.Long())); Topology topology = builder.build(); System.out.println(topology.describe()); KafkaStreams kafkaStreams = new KafkaStreams(topology, config); CountDownLatch countDownLatch = new CountDownLatch(1); try { kafkaStreams.start(); countDownLatch.await(); } catch (InterruptedException e) { log.error("Error occured when countdownlatch await", e); } Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") { @Override public void run() { kafkaStreams.close(); countDownLatch.countDown(); } }); } }
Producer application will create dummy characters and send to “windowedAggregation-source-topic” topic.
package com.onurtokat.stateful_transformations; import com.onurtokat.util.WordCreator; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class WindowedAggProducer { public static void main(String[] args) { //create properties Properties config = new Properties(); config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true); config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //create producer KafkaProducer<String, String> producer = new KafkaProducer<String, String>(config); //create producer record for (int i = 0; i < 100000000; i++) { ProducerRecord<String, String> record = new ProducerRecord<String, String>("windowedAggregation-source-topic", WordCreator.createWord()); producer.send(record); // flush data producer.flush(); } // flush and close producer producer.close(); } }
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic windowedAggregation-source-topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic windowedAggregation-output-topic
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic windowedAggregation-output-topic \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic windowedAggregation-source-topic \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.StringDeserializerEach 5 seconds, stream is being aggregated and written to “windowedAggregation-output-topic” topic.

- Count: It aggregates count of the same keys. Word count case can be a good example of using this method.
package com.onurtokat.stateful_transformations; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.Serdes; import org.apache.kafka.common.utils.Bytes; import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsBuilder; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.Topology; import org.apache.kafka.streams.kstream.*; import org.apache.kafka.streams.state.KeyValueStore; import org.slf4j.Logger; import java.util.Arrays; import java.util.Properties; import java.util.concurrent.CountDownLatch; public class CountTransformation { private static Logger logger; public static void main(String[] args) { //prepare stream Properties config = new Properties(); config.put(StreamsConfig.APPLICATION_ID_CONFIG, "count-transformation-application"); config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> inputStream = builder.stream("count-source-topic2"); KTable<String, Long> resultTable = inputStream .flatMapValues((key, value) -> Arrays.asList(value.split("\\W+"))) .selectKey((key, value) -> value) .mapValues(value -> 1L) .groupByKey(Grouped.<String, Long>as(null) .withValueSerde(Serdes.Long())) .count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>> as("count-stream-store2") .withKeySerde(Serdes.String()) .withValueSerde(Serdes.Long())); resultTable.toStream().to("count-output-topic2", Produced.with(Serdes.String(), Serdes.Long())); Topology topology = builder.build(); System.out.println(topology.describe()); KafkaStreams kafkaStreams = new KafkaStreams(topology, config); CountDownLatch countDownLatch = new CountDownLatch(1); try { kafkaStreams.start(); countDownLatch.await(); } catch (InterruptedException e) { logger.error("Error occured when countdownlatch await", e); } //gracefully shutdown Runtime.getRuntime().addShutdownHook(new Thread("shutdown hook") { @Override public void run() { kafkaStreams.close(); countDownLatch.countDown(); } }); } }
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic count-source-topic2
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic count-output-topic2$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic count-source-topic2 \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic count-output-topic2 \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer


Count (Windowed): It aggregates count of the same keys in a predefined period. Word count case is used for sampling. WindowedCountProducer are created for fluent message flow to topic.
package com.onurtokat.stateful_transformations; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.Serdes; import org.apache.kafka.common.utils.Bytes; import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsBuilder; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.Topology; import org.apache.kafka.streams.kstream.*; import org.apache.kafka.streams.state.WindowStore; import org.slf4j.Logger; import java.time.Duration; import java.util.Arrays; import java.util.Properties; import java.util.concurrent.CountDownLatch; public class WindowedCountTransformation { private static Logger logger; public static void main(String[] args) { //prepare stream Properties config = new Properties(); config.put(StreamsConfig.APPLICATION_ID_CONFIG, "windowed-count-transformation-application"); config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> inputStream = builder.stream("windowed-count-source-topic"); KTable<Windowed<String>, Long> resultTable = inputStream .flatMapValues((key, value) -> Arrays.asList(value.split("\\W+"))) .selectKey((key, value) -> value) .mapValues(value -> 1L) .groupByKey(Grouped.<String, Long>as(null) .withValueSerde(Serdes.Long())).windowedBy(TimeWindows .of(Duration.ofSeconds(5))) .count(Materialized.<String, Long, WindowStore<Bytes, byte[]>> as("windowed-count-stream-store") .withKeySerde(Serdes.String()) .withValueSerde(Serdes.Long())); resultTable.toStream().to("windowed-count-output-topic", Produced.with(WindowedSerdes.timeWindowedSerdeFrom(String.class), Serdes.Long())); Topology topology = builder.build(); System.out.println(topology.describe()); KafkaStreams kafkaStreams = new KafkaStreams(topology, config); CountDownLatch countDownLatch = new CountDownLatch(1); try { kafkaStreams.start(); countDownLatch.await(); } catch (InterruptedException e) { logger.error("Error occured when countdownlatch await", e); } //gracefully shutdown Runtime.getRuntime().addShutdownHook(new Thread("shutdown hook") { @Override public void run() { kafkaStreams.close(); countDownLatch.countDown(); } }); } }
package com.onurtokat.stateful_transformations; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import org.slf4j.Logger; import java.time.LocalTime; import java.util.Properties; import java.util.Random; public class WindowedCountProducer { private static Logger logger; private static final String[] DATA = {"Onur Tokat", "Nazan Tokat", "Ozan Tokat"}; private static final int MAX_CONTENT = 3; private static Random random = new Random(); public static void main(String[] args) { //prepare config Properties config = new Properties(); config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(config); ProducerRecord<String, String> record; StringBuilder sb = new StringBuilder(); //infinite loop while (true) { int tmpCounter = random.nextInt(MAX_CONTENT); for (int i = 0; i <= tmpCounter; i++) { if (i != 0) { sb.append(" " + DATA[random.nextInt(3)]); } else { sb.append(DATA[random.nextInt(3)]); } } record = new ProducerRecord<>("windowed-count-source-topic", "null", sb.toString()); kafkaProducer.send(record); kafkaProducer.flush(); System.out.println(sb + " ## " + LocalTime.now()); try { Thread.sleep(1000); } catch (InterruptedException e) { logger.error("Error occured when Thread sleep", e); } sb = null; sb = new StringBuilder(); } } }
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic windowed-count-source-topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic windowed-count-output-topicbin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic windowed-count-source-topic \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.StringDeserializerbin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic windowed-count-output-topic \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
The created outputs by producer are below;

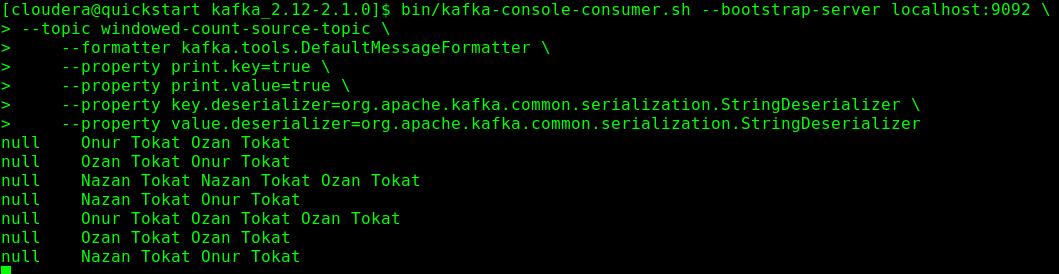

Aggregation period is 5 second. The timestamps of the Producer ouput console is the application process times. They are not exact process time of the Kafka broker and are used for give an idea about windowing of time partials.
Windowing are done by Kafka like below;


- Reduce: Only difference from aggregate method is that reduce method cannot change values which are aggregated by method. output type should be the same with input values.
Method usage examples are taken from Apache Kafka Stream API documentation https://kafka.apache.org/22/documentation/streams/developer-guide/dsl-api.html#aggregating
// Reducing a KGroupedStream
KTable<String, Long> aggregatedStream = groupedStream.reduce(
(aggValue, newValue) -> aggValue + newValue /* adder */);
// Reducing a KGroupedTable
KTable<String, Long> aggregatedTable = groupedTable.reduce(
(aggValue, newValue) -> aggValue + newValue, /* adder */
(aggValue, oldValue) -> aggValue - oldValue /* subtractor */);package com.onurtokat.stateful_transformations; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.Serdes; import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsBuilder; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.Topology; import org.apache.kafka.streams.kstream.Grouped; import org.apache.kafka.streams.kstream.KStream; import org.apache.kafka.streams.kstream.Produced; import org.slf4j.Logger; import java.util.Arrays; import java.util.Properties; import java.util.concurrent.CountDownLatch; public class ReduceTransformation { private static Logger logger; public static void main(String[] args) { //prepare stream Properties config = new Properties(); config.put(StreamsConfig.APPLICATION_ID_CONFIG, "reduce-transformation-application"); config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> kStream = builder.stream("reduce-source-topic"); kStream.flatMapValues(value -> Arrays.asList(value.split("\\W+"))) .selectKey((key, value) -> value) .mapValues(value -> 1L) .groupByKey(Grouped.<String, Long>as(null) .withValueSerde(Serdes.Long())) .reduce((aggValue, newValue) -> aggValue + newValue /* adder */) .toStream().to("reduce-output-topic", Produced. with(Serdes.String(), Serdes.Long())); Topology topology = builder.build(); System.out.println(topology.describe()); KafkaStreams kafkaStreams = new KafkaStreams(topology, config); CountDownLatch countDownLatch = new CountDownLatch(1); try { kafkaStreams.start(); countDownLatch.await(); } catch (InterruptedException e) { logger.error("Error occured when countdownlatch await", e); } //gracefully shutdown Runtime.getRuntime().addShutdownHook(new Thread("shutdownhook") { @Override public void run() { kafkaStreams.close(); countDownLatch.countDown(); } }); } }
package com.onurtokat.stateful_transformations; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import org.slf4j.Logger; import java.time.LocalTime; import java.util.Properties; import java.util.Random; public class ReduceProducer { private static Logger logger; private static final String[] DATA = {"Onur Tokat", "Nazan Tokat", "Ozan Tokat"}; private static final int MAX_CONTENT = 3; private static Random random = new Random(); public static void main(String[] args) { //prepare config Properties config = new Properties(); config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); KafkaProducer<String,String> producer = new KafkaProducer<>(config); ProducerRecord<String,String> record; Random random = new Random(); StringBuilder sb = new StringBuilder(); while (true) { int tmpCounter = random.nextInt(MAX_CONTENT); for (int i = 0; i <= tmpCounter; i++) { if (i != 0) { sb.append(" " + DATA[random.nextInt(3)]); } else { sb.append(DATA[random.nextInt(3)]); } } record = new ProducerRecord<>("reduce-source-topic", "null", sb.toString()); producer.send(record); producer.flush(); System.out.println(sb + " ## " + LocalTime.now()); try { Thread.sleep(1000); } catch (InterruptedException e) { logger.error("Error occured when Thread sleep", e); } sb = null; sb = new StringBuilder(); } } }
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic reduce-source-topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic reduce-output-topic
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic reduce-source-topic \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.StringDeserializerbin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic reduce-output-topic \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
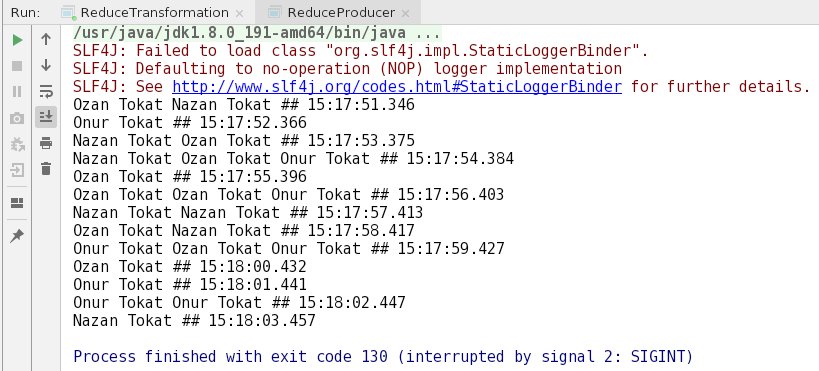
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializerWhen ReduceProducer App is ran, the output is created as below;


- Reduce (windowed): It operates reduce method on predefined time frame. Again, in reduce method, output data type cannot be changed.
Method usage examples are taken from Apache Kafka Stream API documentation https://kafka.apache.org/22/documentation/streams/developer-guide/dsl-api.html#aggregating
// Aggregating with time-based windowing (here: with 5-minute tumbling windows)
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(
TimeWindows.of(Duration.ofMinutes(5)) /* time-based window */)
.reduce(
(aggValue, newValue) -> aggValue + newValue /* adder */
);
// Aggregating with session-based windowing (here: with an inactivity gap of 5 minutes)
KTable<Windowed<String>, Long> sessionzedAggregatedStream = groupedStream.windowedBy(
SessionWindows.with(Duration.ofMinutes(5))) /* session window */
.reduce(
(aggValue, newValue) -> aggValue + newValue /* adder */
);package com.onurtokat.stateful_transformations; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.Serdes; import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsBuilder; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.Topology; import org.apache.kafka.streams.kstream.*; import org.slf4j.Logger; import java.time.Duration; import java.util.Arrays; import java.util.Properties; import java.util.concurrent.CountDownLatch; public class WindowedReduceTransformation { private static Logger logger; public static void main(String[] args) { //prepare stream Properties config = new Properties(); config.put(StreamsConfig.APPLICATION_ID_CONFIG, "windowed-reduce-transformation-application"); config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> kStream = builder.stream("windowed-reduce-source-topic"); kStream.flatMapValues(value -> Arrays.asList(value.split("\\W+"))) .selectKey((key, value) -> value) .mapValues(value -> 1L) .groupByKey(Grouped.<String, Long>as(null) .withValueSerde(Serdes.Long())) .windowedBy(TimeWindows.of(Duration.ofSeconds(5))) .reduce((aggValue, newValue) -> aggValue + newValue /* adder */) .toStream().to("windowed-reduce-output-topic", Produced. with(WindowedSerdes.timeWindowedSerdeFrom(String.class), Serdes.Long())); Topology topology = builder.build(); System.out.println(topology.describe()); KafkaStreams kafkaStreams = new KafkaStreams(topology, config); CountDownLatch countDownLatch = new CountDownLatch(1); try { kafkaStreams.start(); countDownLatch.await(); } catch (InterruptedException e) { logger.error("Error occured when countdownlatch await", e); } //gracefully shutdown Runtime.getRuntime().addShutdownHook(new Thread("shutdownhook") { @Override public void run() { kafkaStreams.close(); countDownLatch.countDown(); } }); } }
Same producer example is used for automatic messages.
package com.onurtokat.stateful_transformations; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import org.slf4j.Logger; import java.time.LocalTime; import java.util.Properties; import java.util.Random; public class WindowedReduceProducer { private static Logger logger; private static final String[] DATA = {"Onur Tokat", "Nazan Tokat", "Ozan Tokat"}; private static final int MAX_CONTENT = 3; private static Random random = new Random(); public static void main(String[] args) { //prepare config Properties config = new Properties(); config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); KafkaProducer<String,String> producer = new KafkaProducer<>(config); ProducerRecord<String,String> record; Random random = new Random(); StringBuilder sb = new StringBuilder(); while (true) { int tmpCounter = random.nextInt(MAX_CONTENT); for (int i = 0; i <= tmpCounter; i++) { if (i != 0) { sb.append(" " + DATA[random.nextInt(3)]); } else { sb.append(DATA[random.nextInt(3)]); } } record = new ProducerRecord<>("windowed-reduce-source-topic", "null", sb.toString()); producer.send(record); producer.flush(); System.out.println(sb + " ## " + LocalTime.now()); try { Thread.sleep(1000); } catch (InterruptedException e) { logger.error("Error occured when Thread sleep", e); } sb = null; sb = new StringBuilder(); } } }
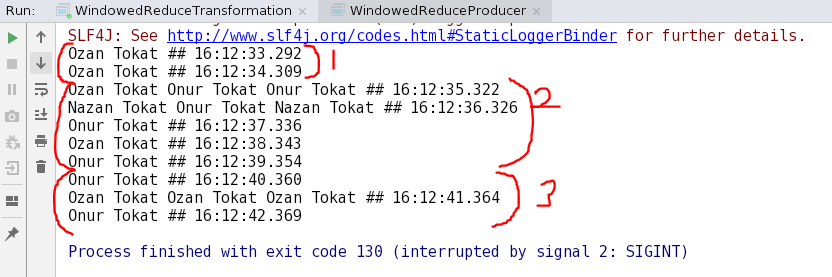
When producer is ran for creating messages, the output is created as below;



The reducing period is 5 seconds. The timestamps of the Producer output console is the application process times. They are not exact process times of the Kafka broker and are used to give an idea about windowing of time partials.
Windowing are done by Kafka like below;